Internet è a un punto di non ritorno. Il continuo aumento del blocco degli annunci ha posto fine al modello di entrate che si basa esclusivamente su dollari pubblicitari per gestire siti Web e aziende.
Soprattutto i siti di notizie hanno iniziato a sperimentare modi per diversificare le fonti di reddito e un'importante opzione che siti come il Wall Street Journal, il Financial Times, il New York Times o il Washington Post hanno tutti implementato è il sistema di paywall.
Esistono diversi tipi di paywalls ma hanno tutti in comune il blocco dell'accesso al contenuto direttamente o dopo che un determinato numero di articoli è stato letto sul sito.
I visitatori sono quindi invitati a iscriversi al sito per continuare a leggere articoli su di esso.
Può avere senso da un punto di vista aziendale e può essere più redditizio che combatterlo con gli utenti che gestiscono gli adblocker, ma c'è un aspetto negativo sia per il sito a pagamento che per l'utente bloccato.
I siti perdono un'alta percentuale di visitatori se implementano un sistema di paywall. Non è chiaro quanto sia realmente alta la percentuale, e probabilmente varia da sito a sito, ma è probabilmente molto più alta della percentuale di visitatori che si abbonano al sito dopo aver ricevuto la scelta di iscriversi per leggere l'articolo desiderato.
Masquerade il tuo browser
Non è un segreto che i siti di notizie consentano l'accesso agli aggregatori di notizie e ai motori di ricerca. Se controlli Google News o Cerca, ad esempio, troverai articoli da siti con paywalls elencati lì.
In passato, i siti di notizie consentivano l'accesso ai visitatori provenienti dai principali aggregatori di notizie come Reddit, Digg o Slashdot, ma questa pratica sembra essere buona come quella dei nostri giorni.
Un altro trucco, per incollare il titolo dell'articolo in un motore di ricerca per leggere direttamente la storia memorizzata nella cache, sembra non funzionare più correttamente, così come gli articoli sui siti con paywall di solito non vengono più memorizzati nella cache.
Aggiornamento : il Wall Street Journal ha annunciato che chiuderà il foro descritto di seguito. Puoi comunque leggere articoli dietro il paywall del sito usando comunque il seguente metodo:
- Premi F12 quando sei nella pagina dell'articolo con l'articolo tagliato e la richiesta di iscrizione per leggerlo per intero.
- Apri la scheda della console.
- Incolla javascript: window.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Premi invio.
La pagina dovrebbe essere ricaricata e l'articolo dovrebbe essere caricato per intero. Puoi anche pubblicare il link dell'articolo su Facebook, ad esempio in un nuovo post che solo tu puoi vedere. Facendo clic sul collegamento pubblicato, l'articolo dovrebbe essere caricato interamente sul sito Web del Wall Street Journal.
User-Agent e Referrer
Probabilmente ti starai chiedendo come i siti bloccano o consentono l'accesso al contenuto del sito. I metodi sono migliorati nel corso degli anni e non è più sufficiente modificare semplicemente il referrer del browser in //www.google.com/ per ottenere pieno accesso al contenuto di un sito.
Invece, i siti utilizzano vari controlli che includono user-agent, referrer e cookie, e talvolta anche di più, per determinare la legittimità dell'accesso.
Informazione generale
Probabilmente il modo migliore per mascherare il browser è far sembrare Googlebot.
- Referente: //www.google.com/
- User-Agent: Mozilla / 5.0 (compatibile; Googlebot / 2.1; + // www.google.com/bot.html
Firefox
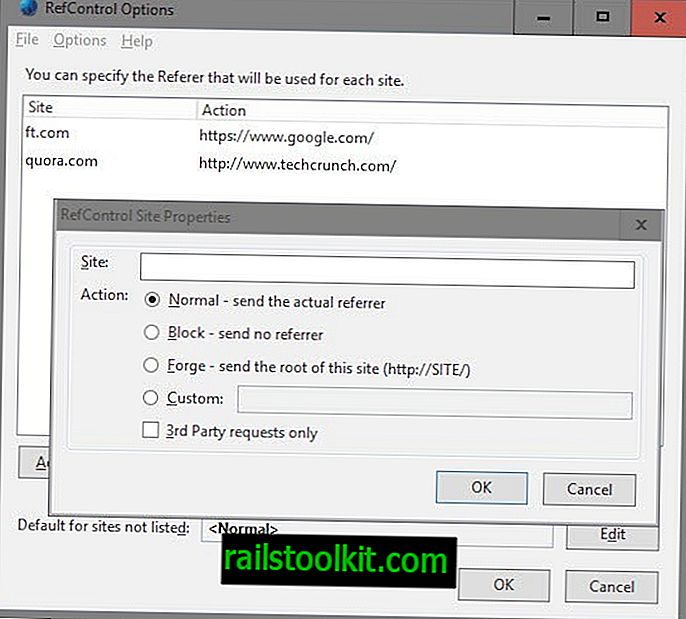
A tale scopo, gli utenti di Firefox hanno bisogno di due componenti aggiuntivi del browser: il primo, RefControl, per modificare il valore del referrer durante la visita di siti di notizie, il secondo, User Agent Switcher, per cambiare l'agente utente del browser.
- Scarica e installa entrambe le estensioni nel browser web Firefox.
- Tocca il tasto Alt e seleziona Strumenti> Opzioni RefControl.
- Fai clic su "aggiungi sito", inserisci un nome di dominio sotto il sito, seleziona l'azione personalizzata e inserisci //www.google.com/ come referrer.
- Ripeti l'operazione per tutti i siti di notizie a cui desideri accedere (alcuni potrebbero non funzionare anche se apporti le modifiche, quindi tienilo a mente).
- Al termine, chiudere la finestra di configurazione.
- Toccare nuovamente il tasto Alt e selezionare Strumenti> Agente utente predefinito> Modifica agenti utente dal menu.
- Seleziona Nuovo> User Agent e sostituisci la stringa nel campo User Agent con Mozilla / 5.0 (compatibile; Googlebot / 2.1; + // www.google.com/bot.html). Chiamalo Googlebot.
- Esci dal menu.
- Prima di accedere a questi siti, tocca Alt e seleziona Agente utente predefinito> Googlebot.
Questo è tutto ciò che c'è da fare. È un po 'un peccato che non vi sia alcuna estensione per Firefox che cambi automaticamente l'agente utente in base ai siti visitati.
Google Chrome
Gli utenti di Google Chrome possono installare estensioni come User Agent Switcher e Referer Control che sono disponibili per il browser per fare lo stesso.
Esiste tuttavia un'altra possibilità, ovvero creare un'estensione personalizzata che automatizza il processo nel browser.
Le istruzioni sono fornite su Elaineou. In pratica, basta creare una nuova directory sul computer locale, creare i due file background.js e manifest.json al suo interno e copiare e incollare il codice trovato nel sito nei file.
È necessario abilitare la "modalità sviluppatore" su chrome: // extensions / e quindi selezionare "carica estensione decompressa" per selezionare la cartella in cui sono stati creati i due file per caricare l'estensione in Chrome.
È possibile modificare l'elenco dei siti supportati per aggiungerne di nuovi.